Inferential statistics (dataset 2)#
Often, we are not only interested in describing our data with descriptive statistics like the mean and standard deviation, but want to know whether two or more sets of measurements are likely to come from the same underlying distribution. We want to draw inferences from the data. This is what inferential statistics is about.
To learn how to do this in python, let’s use some example data:
To test whether a new wonder drug increases the eye sight, Linda and Anabel ran the following experiment with student subjects:
Experimental subjects were injected a saline solution containing 1nM of the wonder drug. Control subjects were injected saline without the drug. The drug is only effective for an hour or so. To assess the effect of the drug, eye sight was scored by testing the subjects’ ability to read small text within one hour of drug injection.
However, Linda and Anabel used two different experimental designs:
Linda tested each student on ten consecutive days and measured the performance only after the experiment. She used 50 control (saline only) and 50 experimental subjects (saline+drug) - so 100 subjects in total.
Anabel only performed a single test per subject, but she measured the eye sight 30 minutes before and 30 minutes after the treatment. She tested 60 different subjects.
Our task is now to decide whether the wonder drug really improves eye sight as tested in these two sets of experiments.
Let’s look at the second dataset.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import scipy
plt.style.use('ncb.mplstyle')
# load and explore the data
df2 = pd.read_csv('dat/5.03_inferential_stats_design2.csv') # Anabel's data
display(df2)
| animal | score_before | score_after | treatment | |
|---|---|---|---|---|
| 0 | 0 | 14.248691 | 9.776487 | 0 |
| 1 | 1 | 9.943656 | 8.854063 | 0 |
| 2 | 2 | 12.730815 | 6.396923 | 0 |
| 3 | 3 | 14.489624 | 9.477586 | 0 |
| 4 | 4 | 11.638078 | 10.501259 | 0 |
| ... | ... | ... | ... | ... |
| 95 | 95 | 13.320677 | 16.738985 | 1 |
| 96 | 96 | 14.809317 | 18.222113 | 1 |
| 97 | 97 | 12.318100 | 12.745123 | 1 |
| 98 | 98 | 12.204639 | 16.840564 | 1 |
| 99 | 99 | 12.621903 | 18.088884 | 1 |
100 rows × 4 columns
What is our Null Hypothesis, what is our Alternative Hypothesis?#
Null hypothesis:
Alternative hypothesis:
We should also formulate hypotheses and test them for the control data. Why?
Let’s plot the data:
# Data from design 2
experiment = df2[df2['treatment']==1]
control = df2[df2['treatment']==0]
ax = plt.subplot(121)
plt.plot(control[['score_before', 'score_after']].T, 'o-k', alpha=0.2)
plt.xticks([0, 1], ['Before', 'After'])
plt.xlim(-0.2, 1.2)
plt.ylabel('Score [%]')
plt.title('Control')
plt.subplot(122, sharey=ax)
plt.plot(experiment[['score_before', 'score_after']].T, 'o-r', alpha=0.2)
plt.xticks([0, 1], ['Before', 'After'])
plt.xlim(-0.2, 1.2)
plt.yticks([8, 12, 16, 20])
plt.title('Experiment')
plt.suptitle('Design2')
plt.show()

Are all samples independent? Are they paired or unpaired?#
Is the data normally distributed?#
# Histogram the data
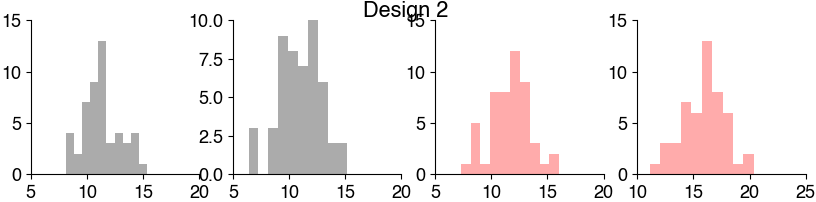
Mini exercise: Test for normality#
# your solution here
Mini Exercise: Run the tests#
We now know all we need to know about our samples to select the correct test:
paired or unpaired: ?
normal: ?
homoscedasticity: ?
one/two-sided: ?
Check the docs to figure out how to use the correct test:
unpaired (independent):
paired (or related):
# your solution here